Recommended material: Udacity AI for Robotics planning lectures, in particular, lectures on Dijkstra’s and A*
In detail: ROS maps doc, ROS local planning doc, ROS global planning doc,
As stated in the previous post, all intelligent robots need a way of modeling the world around it in such a way that the model enables for planned action.
Since we are generally interested in mobile robots, we are led to ask – how can the robot map and model the world around it?
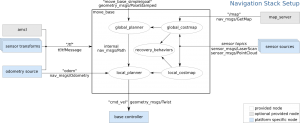
In ROS, the map is a 2D discrete costmap – that is, the map is composed of essentially 2D arrays (so the map is discontinuous to certain extent as the pixels on screens are), of each elements containing the “cost” involved to move the robot to the position of the map.
While the ROS documentation details how exactly the cost can be calculated, the cost largely indicates whether the part of the map is unexplored, blocked off due to an obstacle, or open and available to travel.
As you would guess, the cost is informed by the sensor data (e.g. LIDAR indicating whether the obstacles are located), odometry, and robot localization (how the robot is situated relative within the map).
With the costmap that is generated and updated with new sensor data, the typically utilized strategy for planning out robot movement is to divide the planning into two parts – local planning and global planning. Local planning details how exactly the robot will have to move according to the costmap (and the obstacles listed), while the global planning indicates what general direction the robot should move. This general direction informs the local planning by being involved with the score used for the local planning – closer a particular local plan is to the global plan, more it is incentivized to choose that plan.
In ROS, the local planning only generates the local plan and does not generate the specific motor commands required to actually move the robot by that plan. Instead, local planning node generates the plan, move_base node takes the plan and generates the cmd_vel based on that plan, and a motor controller node (specific to each motor controller and usually written by the robot team) takes the cmd_vel and generates specific motor commands to move the robot in such a way.
This is generally the approach that ROS will take with all hardware. ROS will provide the logic and the abstraction of how the hardware should behave, and the users of ROS will generally have to provide the code that will interface the software and the hardware together.
To go back to the local planning, the details and the steps of it is on the local planning ROS documentation.
Global planning is even more simple – given a current point and point of destination, ROS will generate a global plan using algorithms that will generate the shortest path between the two, an approach simplified as the map is 2D array.
The simplest approach is Dijkstra’s algorithm, which is an algorithm simply calculates the shortest path by checking the distance of all the points beyond the current point.
Another approach is A*, which can be said to be Dijkstra’s algorithm with a heuristic (rule of thumb) attached to it. A* reduces the amount of the distances that needs to be calculated by only calculating points that are likely to lead to shorter path.
Of course, there are many other shortest path algorithms, each with different strengths, but A* and Dijkstra’s algorithm, perhaps due to their simplicity and general effectiveness, is the one supported by the ROS global planner by default.
So, what exactly is the robot doing when it is navigating? It takes the following steps:
- Get a command to go to a particular spot.
- Obtain odometry, sensor data, and robot’s position to model how the robot is situated locally.
- Based on the global plan, choose a local plan that would best follow it while accounting for the obstacles nearby.
- Generate cmd_vel from local plan using move_base node, and generate motor commands using motor controller node
- The robot moves
- Based on the new sensor/map data, update the global plan (obstacle in the global plan should be accomodated).
- Repeat until the point is reached.