Recommended readings/lectures: ROS wiki on Navigation stack, Udacity’s Artificial Intelligence for Robotics (brief discussions of Unit 1, 4), AI page for Wikipedia on paradigms and approaches, ROS Wiki on data types
One of the things that got me involved in robotics was the fact that a good robot have to be a sufficiently intelligent agent – capable of sensing the “right” parts of the environment (computational cost involved in sensing requires that every agent be discerning) and acting real-time based on those decisions.
Thus, the challenges of robotics involve those two questions – how and what should the robot sense in the environment, and how can the robot act based on that data in a way that could mimic the future-planning and strategic agents like us?
First, let us address the first question – what exactly is involved in the robot’s perception of the environment, or phrased more concretely, why is making a perceptive robot difficult?
One cause of difficulty is the inherent uncertainty that comes with perception. Whether it is caused by the environment or the sensors, the uncertainty of perception necessitates that the robots process what they perceive, and discern the probable reality based on their previous perceptions. For example, we humans can discern that the visual illusions are illusions by analyzing the senses and declaring them to be false, based on our limited understanding of our visual system.
The idea of taking bunch of uncertain things to unify them into a more certain conclusion is an essential idea of robotic perception, and it inherently involves probabilities.
Similarly, another cause of difficulty is the difficulty of integrating multiple sensory data to form one (sometimes multiple) coherent model. Effective perceiving agents have multiple kinds of senses. For example, humans have senses of vision, tactile, etc – many of which informing another sense (e.g. food tastes better if you can smell them). Likewise, robots have a wide array of disparate sensors – ranging from LIDAR (distance sensor that uses laser), infrared sensor, wheel encoders (keeps track of wheel rotations) – and they must be able to utilize all of them to deliberate an action (not necessarily a cohesive action, some theory of AI/robotics argue for the possibility of separate sensors and actuators (limbs of robots) within one robot – an arm acting separately from the body, for instance).
Not only can the type of sensor data be different, but the sensory data could be coming from different parts of the robot – a camera on the left arm and a right arm, for instance. Such scenario gives way to its own sets of problems: how do we “sync” up the changes between the two cameras to get the one coherent view of the room? What does the camera on the arms inform us of the situation the robot is in (the body, etc)?
After the issue of the senses and perception, we are then confronted with the issue of acting and planning (for the future). Indeed, any robots worth their money must be able to plan for the future in some way – not only for the effectiveness of the action, but for the intelligence of the robot.
First question we can think of is the issue of producing good models of reality based on the perceptions. Yes, the perception and sensor data may be in, but they are of no use to us (and the robot) if they can’t be modeled and “understood” properly. For example, if the LIDAR returns to us a 2D vector of points as perceived relative to the sensor, how or for what can we use the data?
Another question is a practical one of making real-time decisions based on the model. Even if the robot have the best model in the world, yet if there is no computationally practical way of acting real-time according to the model, then the robot would be terrible and the model useless. While this practical concern had been well mitigated by the Moore’s Law, it is still and will be a concern in the future.
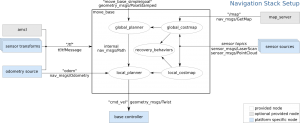
These issues are thankfully addressed to some extent in the ROS library, particular in the part of the library called the navigation stack. Navigation “stack” features many nodes that each deal with an issue.
The navigation stack largely addresses these issues in the context of mobile, autonomous robots. As seen in the diagram below, nodes that deal with sensor data and perception goes into the box part of the diagram, which largely acts as a brain (more specifically, a state machine) that gives out a command for action (cmd_vel and path for the future). With that cmd_vel, the programmers would tell the robot how to move, writing a motor controller program that can receive the commands in terms of cmd_vel.
In the upcoming days, the nodes you’ll interact with will be nodes that will serve to be basic processor for the sensors – taking in perception and providing the data in a specific format.